Maps-kb: A million-scale probabilistic simile knowledge base
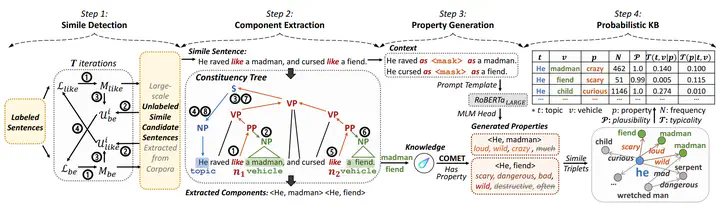 Image credit: Unsplash
Image credit: Unsplash
Abstract
The ability to understand and generate similes is an imperative step to realize human-level AI. However, there is still a considerable gap between machine intelligence and human cognition in similes, since deep models based on statistical distribution tend to favour high-frequency similes. Hence, a large-scale symbolic knowledge base of similes is required, as it contributes to the modeling of diverse yet unpopular similes while facilitating additional evaluation and reasoning. To bridge the gap, we propose a novel framework for large-scale simile knowledge base construction, as well as two probabilistic metrics which enable an improved understanding of simile phenomena in natural language. Overall, we construct MAPS-KB, a million-scale probabilistic simile knowledge base, covering 4.3 million triplets over 0.4 million terms from 70 GB corpora. We conduct sufficient experiments to justify the effectiveness and necessity of the methods of our framework. We also apply MAPS-KB on three downstream tasks to achieve state-of-the-art performance, further demonstrating the value of MAPS-KB. Resources of MAPS-KB are publicly available at https://github. com/Abbey4799/MAPS-KB.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.
Xintao Wang
Ph.D Candidate
My research interests focus on large language models and autonomous agents, especially their personas and personalization.